
Data Chunking Strategies in RAG
On Building Context-Aware Conversational Agents

RAG systems play a crucial role in addressing NLP problems by fetching relevant information or documents based on the input query (Retriever) and generating a coherent, contextually appropriate response (Generator).
While Large Language Models (LLMs) are proficient at understanding languages and come with extensive general knowledge, they lack awareness of the proprietary data that companies handle. Training an LLM with large volumes of proprietary data can be costly, and sometimes data owners are reluctant to share their data with a neural network model, particularly if it isn't self-hosted. Additionally, fine-tuning neural networks has its limitations. Therefore, Retrieval-Augmented Generation (RAG) presents an excellent solution, as its architecture leverages external knowledge and integrates it effectively with the Neural Network (NN) model.
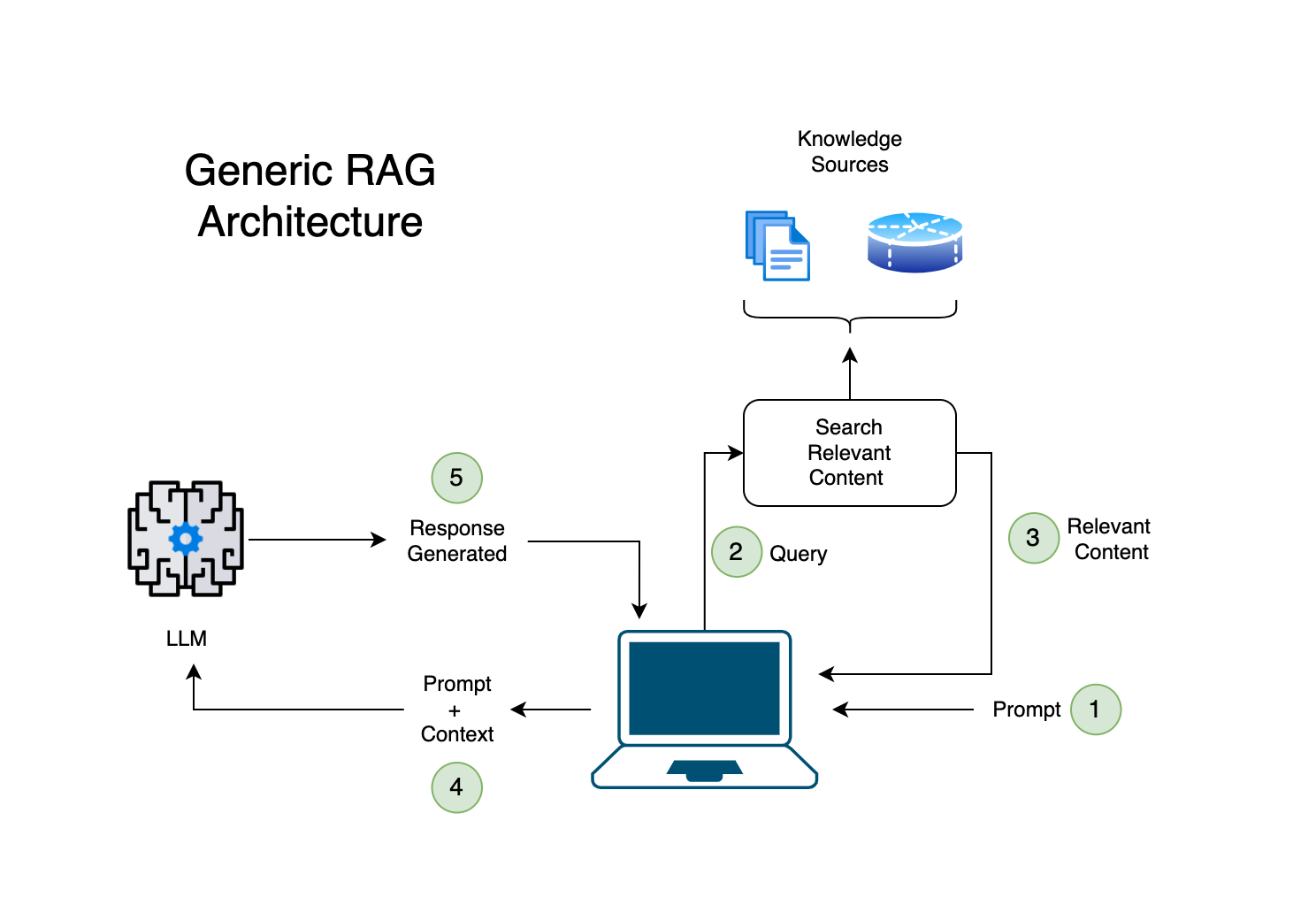
The strength of the RAG system lies in its ability to leverage a vast amount of information that is not stored directly within the model but can be accessed and utilized as needed. This approach helps in generating responses that are not only contextually relevant but also informed by a wide range of sources, making the RAG model particularly useful for applications like chatbots, question-answering systems, and other AI interfaces that require accurate and detailed information retrieval combined with Natural Language Understanding (NLU) and generation.
A RAG system essentially correlates a user's prompt with a relevant data chunk.
It does this by identifying the most semantically similar chunk from the database.
This chunk then becomes the context for the prompt.
When passed to the Large Language Model (LLM), it enables the system to provide a relevant answer within the given context.
LLMs also have a limited capacity for context. Just as humans cannot digest unlimited context, these models have a specific size limit for the context they can process.
So, what about situations involving very large amounts of data? Consider a specific use case, such as a book. It's too large to pass the entire book as the context for the current prompt, so it needs to be divided before being stored in the database.
This process is known as data chunking.

So, how do we choose to split data?
The definitive factor of the decision is of course the size of the context window that can be passed to the NN model. The size of the data chunk cannot exceed this limit and we should also consider reserving space for the prompt size. They are sent together to the model.
Here we have different methods.
Fixed-size chunking
This method is the most basic and can be efficient in most cases, especially when the data source is not overly large. We simply determine the number of tokens in each chunk and, optionally, decide if there should be any overlap between them. Generally, maintaining some overlap between chunks is recommended to ensure that the semantic context isn’t lost. Fixed-sized chunking is often the best approach in common cases due to its speed, making it a cost-effective method.
def fixed_chunking(text, chunk_size):
return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]
# Example
text = "Your long text here..."
chunk_size = 100 # fixed size of each chunk
chunks = fixed_chunking(text, chunk_size)Variable chunking
This method is used when more fine-tuning is required in data splitting. While keeping in mind the hard upper limit of chunk size, any size under that limit can also be effective, often yielding better results. Various techniques for variable chunking include:
Sentence Splitting (Naive Approach): The most basic approach is to split sentences by periods (“.”) and new lines. Although fast and simple, this method may not account for all possible edge cases.
def naive_sentence_splitting(text): return text.split('. ') # Example text = "Your long text here..." chunks = naive_sentence_splitting(text)Sentence Splitting (Using NLP Libraries): Libraries such as NLTK (Natural Language Toolkit) or spaCy are useful. NLTK, a popular Python library for processing human language data, offers a sentence tokenizer that splits text into sentences, aiding in creating more meaningful chunks.
# Using NLTK import nltk nltk.download('punkt') from nltk.tokenize import sent_tokenize def nltk_sentence_splitting(text): return sent_tokenize(text) # Using spaCy import spacy nlp = spacy.load('en_core_web_sm') def spacy_sentence_splitting(text): doc = nlp(text) return [sent.text for sent in doc.sents] # Example text = "Your long text here..." nltk_chunks = nltk_sentence_splitting(text) spacy_chunks = spacy_sentence_splitting(text)Recursive Chunking: This approach divides the input text into smaller chunks in a hierarchical and iterative manner, using a set of separators. If the initial splitting does not yield the desired chunk size or structure, the method recursively applies itself to the resulting chunks with different separators or criteria. This means the chunks might not be exactly the same size, but they will generally be similar.
def recursive_chunking(text, max_length): if len(text) <= max_length: return [text] else: # Find a suitable split point (e.g., end of a sentence) split_point = text.rfind('. ', 0, max_length) + 1 return [text[:split_point]] + recursive_chunking(text[split_point:], max_length) # Example text = "Your long text here..." max_length = 100 chunks = recursive_chunking(text, max_length)Specialized Chunking for Markdown, HTML, LaTeX, etc.: This involves first removing tags, and then filtering the raw text while maintaining its integrity. Subsequently, a different chunking strategy is applied."
from bs4 import BeautifulSoup def html_chunking(html_content): soup = BeautifulSoup(html_content, 'html.parser') return [str(tag) for tag in soup.find_all()] # Example html_content = "<html>Your HTML content here...</html>" chunks = html_chunking(html_content)
Semantic chunking
This method is my personal favourite. It involves distinguishing different topics within the data source and chunking them separately.
Semantic chunking is a more complex form of variable chunking. It incorporates an additional Natural Language Understanding (NLU) layer in the data chunking process.
# This is a simplified example using spaCy for NLP
import spacy
nlp = spacy.load('en_core_web_sm')
def semantic_chunking(text, threshold=0.7):
doc = nlp(text)
chunks = []
current_chunk = []
for sent in doc.sents:
if current_chunk:
similarity = nlp(" ".join(current_chunk)).similarity(sent)
if similarity < threshold:
chunks.append(" ".join(current_chunk))
current_chunk = [sent.text]
else:
current_chunk.append(sent.text)
else:
current_chunk.append(sent.text)
if current_chunk:
chunks.append(" ".join(current_chunk))
return chunks
# Example
text = "Your long text here..."
chunks = semantic_chunking(text)In brief, the algorithm works as follows:
Take a variable chunk of data and analyze it with an LLM (Large Language Model).
If it relates to the previous chunk, add it there; otherwise, create a new chunk as a new topic.
Check if the topic is becoming too large. If so, apply recursive variable semantic chunking.
Additionally, for every initial variable chunk, consider creating a summary. This way, both the raw chunked data and chunked summaries are stored, maximizing the chances of obtaining relevant contexts.
def advanced_semantic_chunking(text, llm, threshold=0.7, max_chunk_size=500):
# Split the text into basic chunks first (e.g., sentences)
basic_chunks = naive_sentence_splitting(text)
advanced_chunks = []
current_chunk = []
for chunk in basic_chunks:
if current_chunk:
# Analyze chunk with LLM
is_related = llm.analyze_similarity(current_chunk, chunk)
if not is_related or len(" ".join(current_chunk)) > max_chunk_size:
advanced_chunks.append(" ".join(current_chunk))
current_chunk = [chunk]
else:
current_chunk.append(chunk)
else:
current_chunk.append(chunk)
if current_chunk:
advanced_chunks.append(" ".join(current_chunk))
return advanced_chunks
# This function requires an LLM setup for 'llm.analyze_similarity'Semantic chunking is a technique not always worth implementing due to its higher cost. However, in edge cases with very complex content, it proves to be the most efficient approach.
Further improvements
In addition to the core semantic chunking strategy, there are several advanced techniques, algorithms and architectures that can be integrated to significantly enhance the accuracy and relevance of results in a RAG system.
These enhancements include the use of complex retrieval methods, integration of advanced neural network architectures in the retriever component, incorporation of attention mechanisms, employing techniques such as query expansion, usage of ensemble methods and adaptive methods, and even implementation of continual learning models.
By integrating these advanced techniques and architectures with semantic chunking, a RAG system can achieve a higher level of precision and accuracy, making it a powerful tool for complex information retrieval and language understanding tasks.
Follow me for more content like this.
References
Semantic Chunking in Practice [Visited on February 22, 2024]
Semantic Chunking in Langchain [Visited on February 22, 2024]
Semantic Chunker in LlamaIndex [Visited on February 22, 2024]
Chunking Strategies [Visited on February 24, 2024]
LangChain: How to Properly Split Your Chunks [Visited on February 20 2024]
Semantic-Text-Splitter - Create meaningful chunks from documents [Visited on February 21, 2024]
Semantic Chunking [Visited on February 22, 2024]
The 5 Levels Of Text Splitting For Retrieval [Visited on February 23, 2024]
Chunking methods for LLMs [Visited on February 24, 2024]